

In order to measure and verify the accuracy of the recommender the Duine Framework offers a validation tool. You can apply this tool for your system when you have some test data available. The assumed test data for the validation engine tool is the usage log of users. What ratings did they provide on information items, what interests have been explicitly updated etc.
In many cases, especially for entirely new systems, such log data is not yet available. A common approach is to start with educated guesses (or advice from experts) for the values of tuning attributes and have a pilot test of your application with users. During the pilot you should have the logging service of the framework activated. The log database of the pilot can than be used as test data set for further validation and optimization.
It is advisable to do validation tests every now and then in order to optimize the tuning attributes to any changes in the usage of your system. If you are adding new prediction techniques to your system validation is also very helpful in verifying the improvement of the recommendations.
The Validation Framework is shown below.
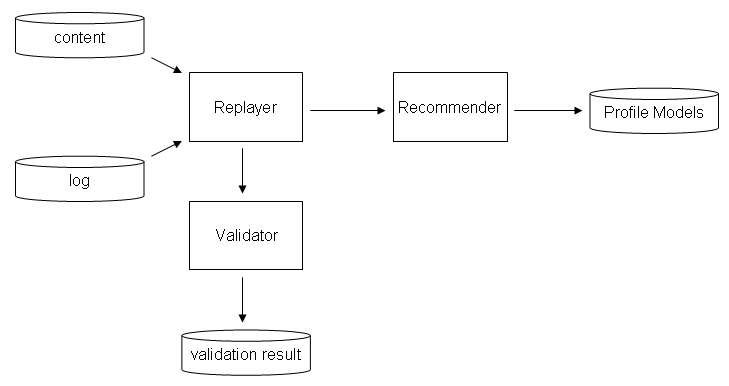
The "workhorse" of the framework is the replayer. The replayer reads the database with the usage log of users. For each log entry it calls enterFeedback(..) on the recommender. The recommender will perform its calculations and update the profile models as usual. Note that the replayer needs access to a content database. This is because the log database only contains id's of items. The recommender needs item objects, so to construct these objects access to the content database is needed.
The replayer allows registration of replayer listeners. These listeners are called just before the replayer calls enterFeedback(..) on the recommender. The Duine Framework has a validating replayer listener. This validator has its own database with validation results. When it is called by the replayer it stores the feedback value for the current item (the rating) and subsequently asks each individual predictor of the recommender for a prediction for this item and stores the result.
Having these data we can compare the prediction value for each predictor with the actual rating that the user gave, and we have a metric of how accurate each predictor is.
The demo uses the validation framework to measure the accuracy of the Duine recommender (having its default configuration). We decided to use the MovieLens data set as many recommender system research projects have experimented with this publicly available data set. The data set consists of ratings of movies. Before we are able to do a Duine validation run we will have to convert this dataset into the Duine usage log format. Once we have created this log database we can use the replayer and associated validator as described before.
The entire blueprint of tools and databases required for this demo is shown in the figure below. The entire structure is wired together by means of configuration files.
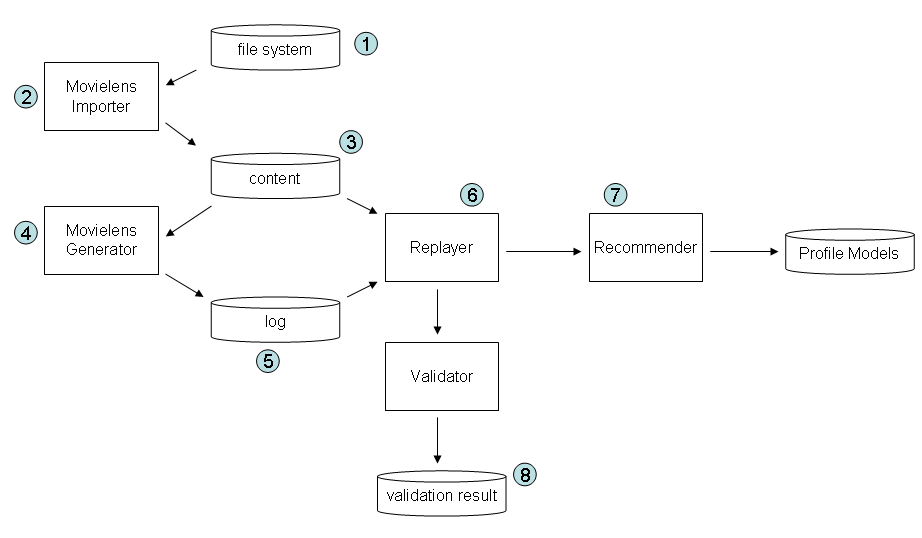
Download and unpack the movielens data (100.000 version) from http://www.grouplens.org . The directory with the movielens data will be referred to as MOVIELENS_DIR. (1)
Instructions for creation and configuration of the databases are provided in the Getting Started (1) - Installation section. The MovieLens validation demo can only run against MySQL.
In addition to the instructions you will have to set the property movielens.directory in the configuration file spring-datasources.properties to the path to the MOVIELENS_DIR.
A note on deployment: we found that best system performance is achieved by deploying the MySQL database server on Linux. The table below gives an indication of the huge differences.
| Duine on Windows - MySQL on Windows | Duine on Windows - MySQL on Linux | Duine on Linux - MySQL on Linux | |
| Importer | 40 minutes | 2 minutes | 20 seconds |
| Log generator | 37 minutes | 3 minutes | 1 minute |
Goal : Import the relevant movielens data from the filesystem into a mysql table for further processing. We will refer to the table with imported data as duine_movielens_content . (3)
WARNING: Running the importer will clear the existing duine_movielens_content .
Run the importer (2): Run the java main program MovielensImporter.java (in the validation package).
Goal : Transform the imported movielens data in duine_movielens_content into a Duine log table (to be referred to as duine_movielens_log (5)). The resulting table represents the movielens data in the same format that is used by the Duine logging component, as if the movielens data was created by Duine instead of the proprietary movielens rating implementation. The advantage of this format is that it can be replayed by the Duine replayer (next section).
WARNING: Running the log generator will clear the existing duine_movielens_log .
Run the generator (4): Run the java main program MovieLensGenerator.java (in the validation package).
Goal : Compare the ratings of the movielens user with the values that are predicted by the recommender (7). Results are stored in duine_movielens_validationresult (8)
Configuration : In spring-datasources.xml you will have to modify 2 data sources. Look for recommender.dataSource to configure the database that the recommender uses to store and access profile models. Look for movielens.validationresult to configure the database for the validation results.
WARNING: Running the replayer will clear the existing duine_movielens_validationresult . It is recommended to create a database backup after a replayer run.
Run the replayer (6): Run the java main program MovieLensValidator.java (in the validation package). Note that this run can take several hours. Before running the Replayer you can delete some data from the duine_log table in the duine_movielens_log database to reduce waiting time, for example:
DELETE FROM duine_log WHERE USER_ID >10;
After a validation run has completed, the table duine_validation_result in database duine_movielens_validationresult contains for every prediction and for every predictor data about the prediction, the actual rating of the user, the error of the prediction, the certainty of the prediction, which user and which item. Based on this data, you can easily calculate the accuracy of each prediction technique and strategy.
The accuracy of predictions is based on the knowledge of the actual interest of the user, which is known via the feedback provided by the user: the rating, and the prediction of the technique of strategy. The absolute difference between the rating and the prediction is the prediction error. E.g. if the prediction is 0.5 and the user rated the item with a 1, the prediction error is 0.5
prediction_error = |prediction - rating|
The overall accuracy of a prediction technique or strategy is now simply average of all those errors. The lower this average is, the better the technique or strategy predicts the interests of the users. In order to list the accuracy of all prediction techniques and strategies from a validation run, one can use the following SQL statement :
select technique, avg(abs(error)) from duine_validation_result group by technique
Notice that the accuracy measure uses the default neutral prediction value of 0 when a predictor is not capable of providing a prediction. If you want to test how accurate predictors are when the can actually provide a prediction, you should alter the SQL statement into:
select technique, avg(abs(error)) from duine_validation_result where certainty > 0.01 group by technique
All predictors that cannot provide a prediction will have a certainty of about 0 for their prediction. For this reason, if only predictions are used that have a certainty of larger than 0.01 you should only get real predictions.